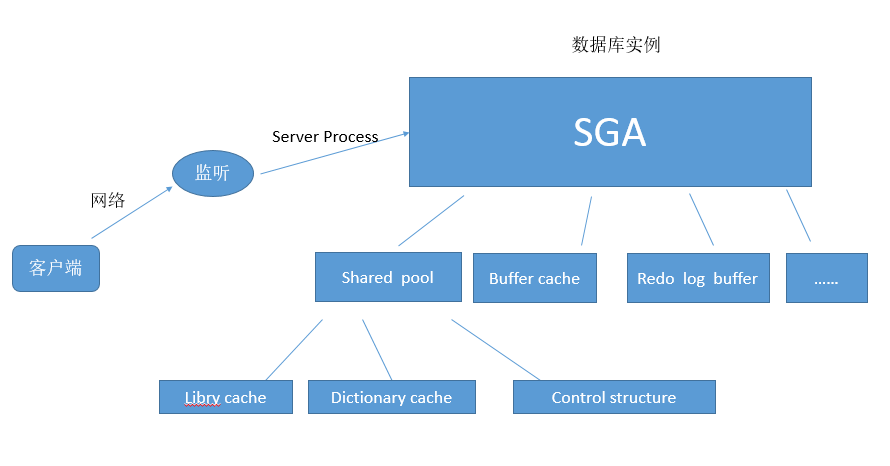
一、客户端通过监听连接到数据库,数据库开启一个server process进程来接收客户端传过来的sql。
1.这条sql语句从来都没有被执行过。(硬解析)
2.这条sql语句被执行过。(软解析)
二、我们来看一条SQL语句内部解析到底经历了什么?
sql硬解析解析的步骤
1.语法检测:检测sql语句有没有语法错误,是否符合sql规范
2.语义检测:检测sql语句涉及的对象是否存在。 3.检查共享池中是否存在相同的已经执行过的sql语句。 4.通过数据字典的统计信息,来计算最优执行计划。5.拿到执行计划后就要去buffer cache中找数据,如果数据不在buffer cache中缓存着,那么就到数据库中将数据读进来。将数据保存到buffer cache 中,而执行计划也会被保存到library cache中去。
6.拿到数据后就要对数据进行操作后返回给用户,至此,在执行的这条sql要了哪些数据,改变了什么内容这些痕迹都会被保存到redo log buffer 中去,然后被归档到归档文件中。
7.这样硬解析的过程到此结束。
sql软解析解析的步骤
1.语法检测:检测sql语句有没有语法错误,是否符合sql规范
2.语义检测:检测sql语句涉及的对象是否存在。3.检查共享池中是否存在相同的已经执行过的sql语句。如果有,则直接使用执行计划。4.拿到执行计划后就要去buffer cache中找数据,如果数据不在buffer cache中缓存着,那么就到数据库中将数据读进来。将数据保存到buffer cache 中,而执行计划也会被保存到library cache中去。
5.拿到数据后就要对数据进行操作后返回给用户,至此,在执行的这条sql要了哪些数据,改变了什么内容这些痕迹都会被保存到redo log buffer 中去,然后被归档到归档文件中。
6.这样硬解析的过程到此结束。
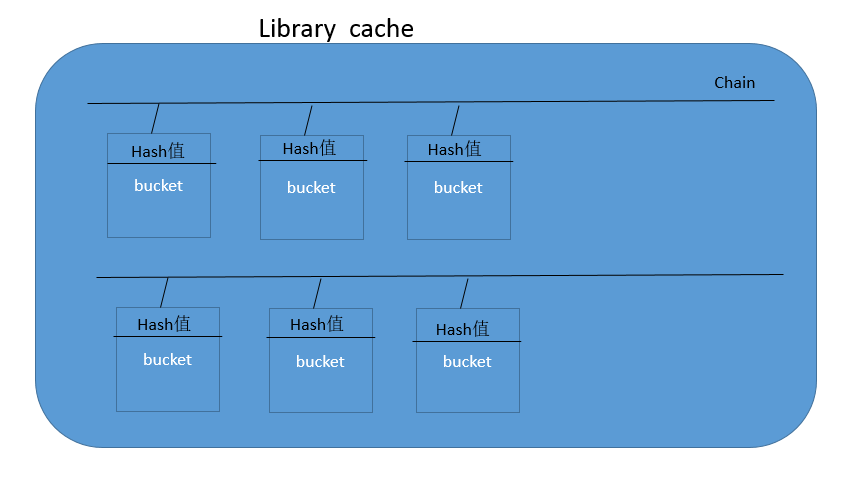
三、检查共享池中是否存在相同的已经执行过的sql语句的方法:
1.将sql文本转换成ASCII值,再将ASCII值通过hash函数转换成hash值,根据计算出来的hash到library cache中的chain链上去找到对于的bucket.比较bucket是否存在这条sql语句。至于library cache 的内部是使用链的数据结构的形式来管理内存的,library cache里面有很多的chain链,每个链上又挂着很多的bucket。bucket里面存放的是sql语句文本,执行计划等。